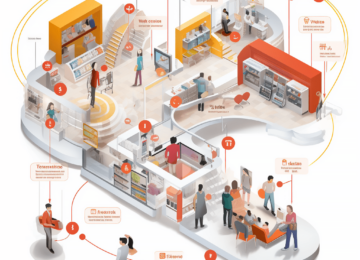


Comme des milliers de commerçants, réduisez vos pertes liées au vol jusqu’à 60% ! Veesion utilise la puissance de l’intelligence artificielle pour détecter et prévenir les vols dans votre magasin.

Installez le logiciel Veesion dans votre supermarché classique, bio ou spécialisé.

Installez Veesion dans votre pharmacie et recevez des alertes sur vos caisses enregistreuses.

Installez Veesion dans votre magasin de cosmétiques, de bricolage, de vêtements et de logistique.

100,000
gestes suspects détectés chaque mois
+3,000
magasins equipés dans le monde
+25
pays conquis
60%
de réduction potentielle de la démarque

ETUDES DE CAS
Découvrez comment Veesion a permis de répondre aux enjeux de sécurité de divers commerçants, de toutes tailles et de tous secteurs.
Les produits de parapharmacie sont la cible de bandes organisées car cela se revend très facilement: il nous est impossible de tout antivoler et Veesion nous a permis de réduire notre démarque inconnue.

Pharmacien titulaire Pharmabest
Avec plus de 120 caméras, il est impossible d’exploiter efficacement l’ensemble de notre système de vidéo-protection : l’IA nous permet de gagner du temps en étant au bon endroit au bon moment.

Adhérent Leclerc
Veesion est le troisième oeil de mon magasin, il détecte les gestes suspects que nous ne pouvons pas voir.

Gérant Carrefour City
Je savais que j’étais victime de vols commis par des clients réguliers, je peux maintenant éviter que cela se reproduise : à la fin de l’année, ce sont des sommes très élevées.

Gérant supermarché G20
Grâce à Veesion, on a démantelé un réseau de professionnels du vol à l’étalage qui ciblait plusieurs magasins de la région !

Adhérent Intermarché
On retrouvait des antivols un peu partout et pas seulement dans les cabines d’essayage ! On a pu mettre fin à une série de vols sur des articles à forte valeur faciale grâce aux alertes Veesion.

Franchisé Intersport
Avec Veesion, je peux enfin utiliser mes caméras en temps réel, sans pour autant rester devant toute la journée !
Adhérent Intermarché
Depuis que j’ai installé Veesion, j’ai constaté une diminution significative des vols dans mon établissement, ce qui a permis de réduire la démarque inconnue.

Pharmacien titulaire Apothical
Des milliers de magasins
et d’entreprises équipés
dans plus de 25 pays
Vous avez un ou plusieurs magasins ? Notre équipe revient vers vous dans les 48h.